Common Functions
str_locate_all, str_sub, substr, gsub, read_html, html_text, html_nodesR has some useful packages to deal with web scraping. A personal favorite is rvest. Full script for the example, in both text and picture form (to account for inconsistencies in display style), is at the bottom of the page.
install.packages("rvest")
library(rvest)As an example, imagine we have a list of MLB players in an Excel document for whom we’d like to extract basic information on, such as height and weight.
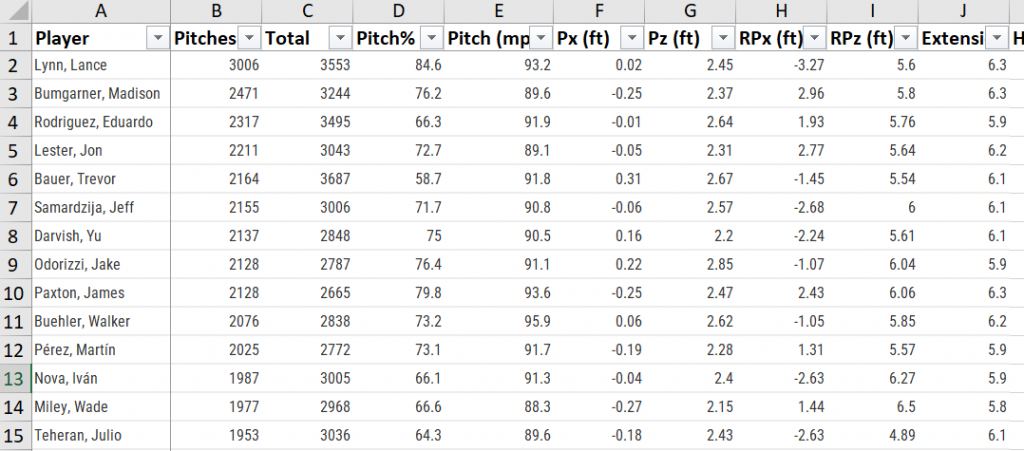
One website, Baseball Reference, conveniently stores this information.
Grabbing XPath
To grab this information, one can first copy the valid XPath. First use the inspect tool (right click->inspect), then click on desired element of web page, and click on the left three dots to copy the XPath.
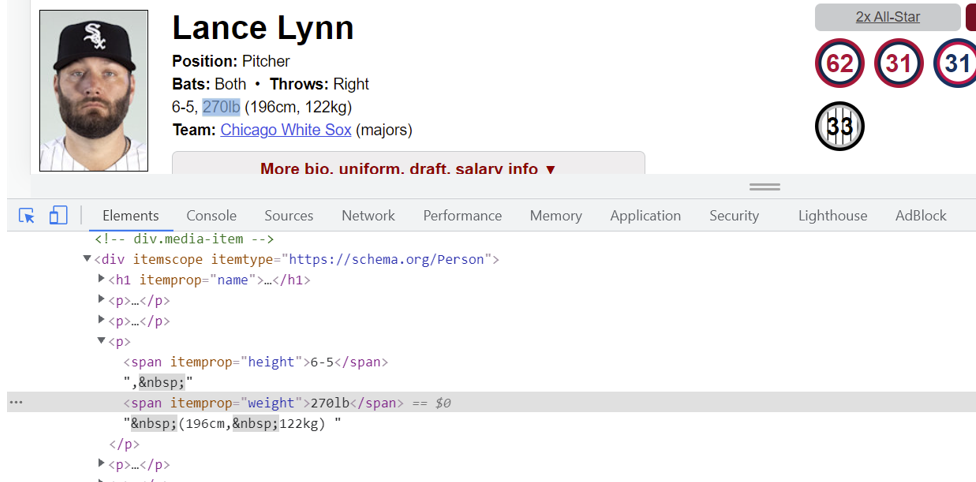
Finding URL Convention
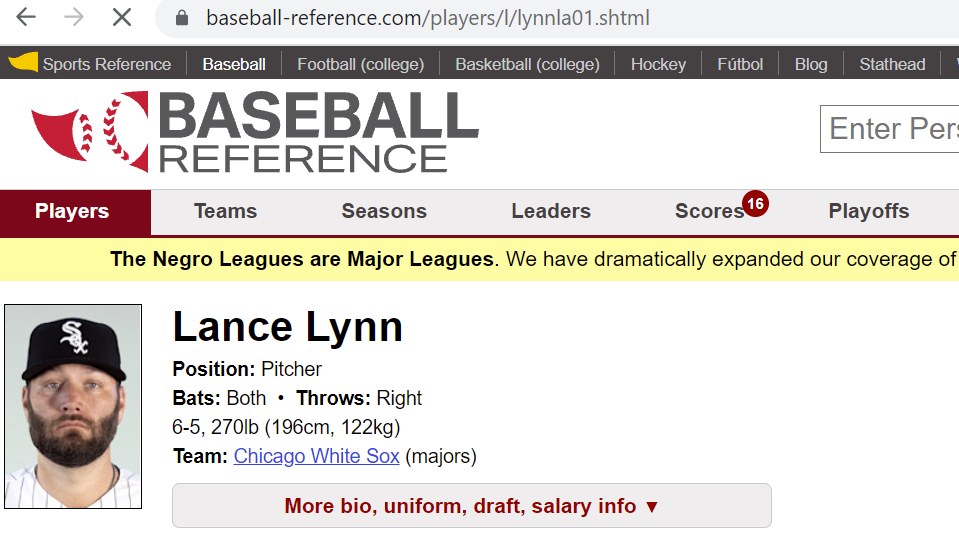
We continue our preparation by examining the url of the webpage: “baseball-reference.com/players/l/lynnla01.com.shtml”. By looking at a few other players, a pattern emerges in the url convention: “baseball-reference.com/players/” followed by the initial of the last name, another forward slash, the first five letters of a player’s last name, the first two letters of a player’s first name, and finally “01.com.shtml” (or “02.com.shtml” and so on if there are multiple players with the same name).
To assemble this information in our script, we need to separate “last_name, first_name” into the first and last name, disregarding capital letters and spaces, and adjusting special characters (such as those with accents).
First we load the data:
mydata=read.csv("C:/filepath/Release Point.csv")
mlbdata=mydata[,c(1,2,3,5,6,9:11)] #reduce dataset to what is needed#
str(mlbdata) #get a sense of the data#
summary(mlbdata)
save(mlbdata,file="mlbdata.Rda") #for ease of future use#
load('mlbdata.Rda')To separate the name, we first find the location of the comma in the string.
mycoms=str_locate_all(pattern =',', mlbdata[,"Player"]) #location of comma#
mycoms[[1]] #look at data#
start end
#example#
[1,] 5 5 #need to extract just the number#
coms=vector() #create vector "coms"#
for (i in 1:length(mycoms)) { #loop through list to get just the number#
coms[i]=mycoms[[i]][2]
} Next we use the stringr package to get the characters to the left and right of the comma.
install.packages("stringr")
library(stringr)
first_name=tolower(str_sub( #make sure result is lower case#
mlbdata[,"Player"], coms+2)) #from 2nd character after comma to end#
last_name=tolower(str_sub( #make sure result is lower case#
mlbdata[,"Player"], 1, coms-1)) #from 1st character to first before comma#To match the url specifications, we perform a few operations on the first and last names
first_convention=first_name %>% #url format uses first 2 "normal" letters of first name#
iconv(., from="UTF-8", to='ASCII//TRANSLIT') %>% #replace any accent marks#
gsub("'", "", .) %>% #replace spaces with blanks#
gsub(" ", "", .) %>% #replace apostrophes with blanks#
gsub('\\.', "", .) %>% #replace periods with blanks#
substr(., 1, 2) #only use the first 2 letters#
last_convention=last_name %>% #url format uses first 5 "normal" letters of last name#
iconv(., from="UTF-8", to='ASCII//TRANSLIT') %>% #replace any accent marks#
gsub("'", "", .) %>% #replace spaces with blanks#
gsub(" ", "", .) %>% #replace apostrophes with blanks#
gsub('\\.', "", .) %>% #replace periods with blanks#
substr(., 1, 5) #only use the first 5 letters#
initial=substr(last_convention, 1,1) #url format precedes name with initial#We can finally build our url convention
name_convention=paste0(initial, "/", #cumulative url convention#
last_convention,
first_convention,
"01")Looping Over URLs
To scrape multiple pages at once, we use the naming convention described above in concert with the shared url path
url="https://www.baseball-reference.com/players/" #preceeding url#
weight=vector() #create vector "weight"#
for (i in 1:length(name_convention)) {
tryCatch({ #ignore any errors#
a=read_html(paste0(url, name_convention[i], ".shtml"))
b=html_nodes(a, xpath="//*[@id='meta']/div[2]/p[3]/span[2]") #weight#
c=html_text(b)
weight[i]=as.numeric(substr(c, 1, 3)) #remove lbs#
}, error=function(e){cat("ERROR :",conditionMessage(e), "\n")})
}Rvest Functions
Three of the functions above come from the rvest package. Both read_html and html_text are self-expanitory. The middle function, html_nodes, uses the xpath we copied earlier. Of note is that the XPath as copied directly from the inspect tool uses double quotes: //*[@id=”meta”]/div[2]/p[3]/span[2]. To prevent R from closing the string too early, we change these to single quotes.
Full Script
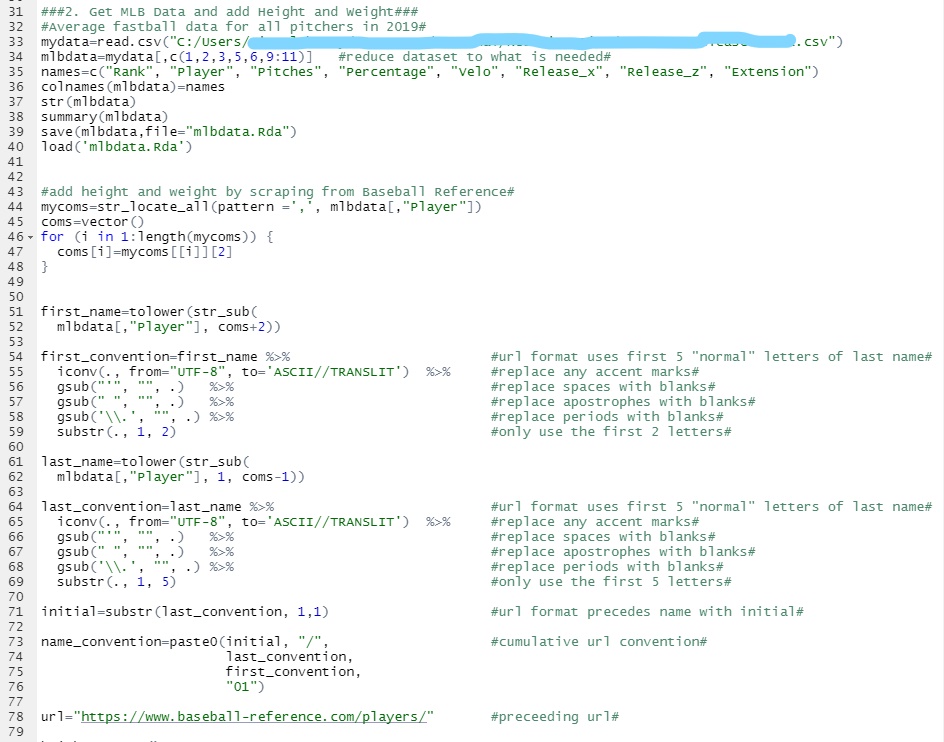
To account for differences in display style, an image of the code is pasted underneath the text below.
#####Written By Liam Flaherty#####
###1. Load requisite packages###
install.packages("rvest")
install.packages("tidyverse")
library(rvest)
library(tidyverse)
###2. Get MLB Data and add Height and Weight###
#Average fastball data for all pitchers in 2019#
mydata=read.csv("C:/file_path/2019 MLB Release Point.csv")
mlbdata=mydata[,c(1,2,3,5,6,9:11)] #reduce dataset to what is needed#
names=c("Rank", "Player", "Pitches", "Percentage", "Velo", "Release_x", "Release_z", "Extension")
colnames(mlbdata)=names
str(mlbdata)
summary(mlbdata)
save(mlbdata,file="mlbdata.Rda")
load('mlbdata.Rda')
#add height and weight by scraping from Baseball Reference#
mycoms=str_locate_all(pattern =',', mlbdata[,"Player"])
coms=vector()
for (i in 1:length(mycoms)) {
coms[i]=mycoms[[i]][2]
}
first_name=tolower(str_sub(
mlbdata[,"Player"], coms+2))
first_convention=first_name %>% #url format uses first 2 "normal" letters of first name#
iconv(., from="UTF-8", to='ASCII//TRANSLIT') %>% #replace any accent marks#
gsub("'", "", .) %>% #replace spaces with blanks#
gsub(" ", "", .) %>% #replace apostrophes with blanks#
gsub('\\.', "", .) %>% #replace periods with blanks#
substr(., 1, 2) #only use the first 2 letters#
last_name=tolower(str_sub(
mlbdata[,"Player"], 1, coms-1))
last_convention=last_name %>% #url format uses first 5 "normal" letters of last name#
iconv(., from="UTF-8", to='ASCII//TRANSLIT') %>% #replace any accent marks#
gsub("'", "", .) %>% #replace spaces with blanks#
gsub(" ", "", .) %>% #replace apostrophes with blanks#
gsub('\\.', "", .) %>% #replace periods with blanks#
substr(., 1, 5) #only use the first 5 letters#
initial=substr(last_convention, 1,1) #url format precedes name with initial#
name_convention=paste0(initial, "/", #cumulative url convention#
last_convention,
first_convention,
"01")
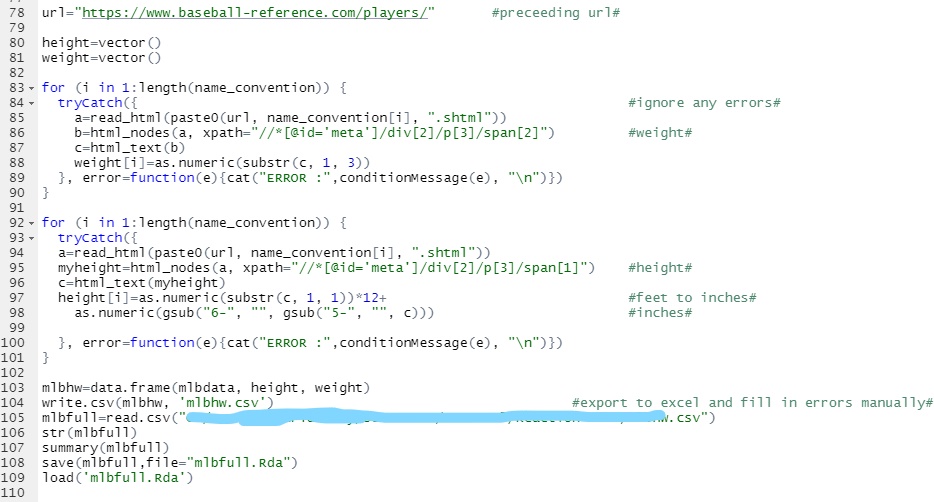
url="https://www.baseball-reference.com/players/" #preceeding url#
height=vector()
weight=vector()
for (i in 1:length(name_convention)) {
tryCatch({ #ignore any errors#
a=read_html(paste0(url, name_convention[i], ".shtml"))
b=html_nodes(a, xpath="//*[@id='meta']/div[2]/p[3]/span[2]") #weight#
c=html_text(b)
weight[i]=as.numeric(substr(c, 1, 3))
}, error=function(e){cat("ERROR :",conditionMessage(e), "\n")})
}
for (i in 1:length(name_convention)) {
tryCatch({
a=read_html(paste0(url, name_convention[i], ".shtml"))
myheight=html_nodes(a, xpath="//*[@id='meta']/div[2]/p[3]/span[1]") #height#
c=html_text(myheight)
height[i]=as.numeric(substr(c, 1, 1))*12+ #feet to inches#
as.numeric(gsub("6-", "", gsub("5-", "", c))) #inches#
}, error=function(e){cat("ERROR :",conditionMessage(e), "\n")})
}
mlbhw=data.frame(mlbdata, height, weight)
write.csv(mlbhw, 'mlbhw.csv') #export to excel and fill in errors manually#
mlbfull=read.csv("C:/filepath/mlbhw.csv")
str(mlbfull)
summary(mlbfull)
save(mlbfull,file="mlbfull.Rda")
load('mlbfull.Rda')